 规划问道
规划问道
地理时空动态模拟工具介绍(上)



FLUS (Future Land Use Simulation model)是模拟人类活动与自然影响下的土地利用变化以及未来土地利用情景的模型。该模型源自元胞自动机(Cellular Automata),并在传统元胞自动机的基础上做了改进。
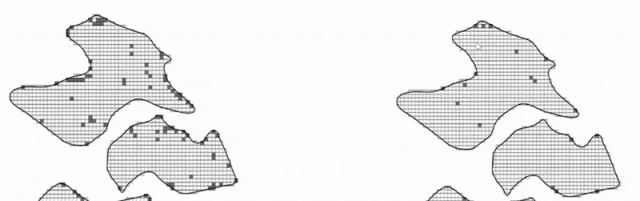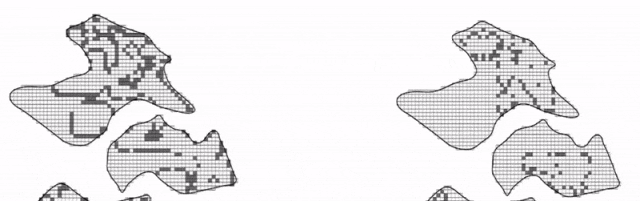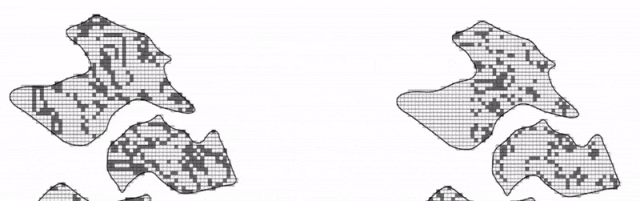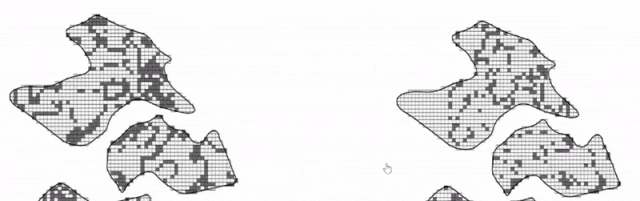
图 转换规则不同,属性值不同
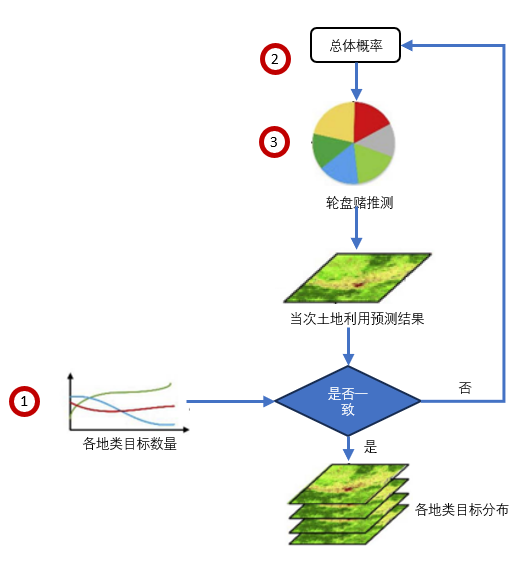
图 FLUS大致流程
第一步预设未来各土地利用类型的数量

图 各地类初始及目标数量
第二步提供各地类转换的总体概率

图 适宜性概率

图 ANN结构

图 邻域权重
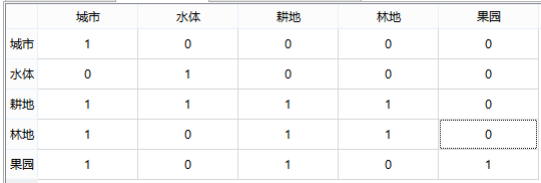
图 转换成本
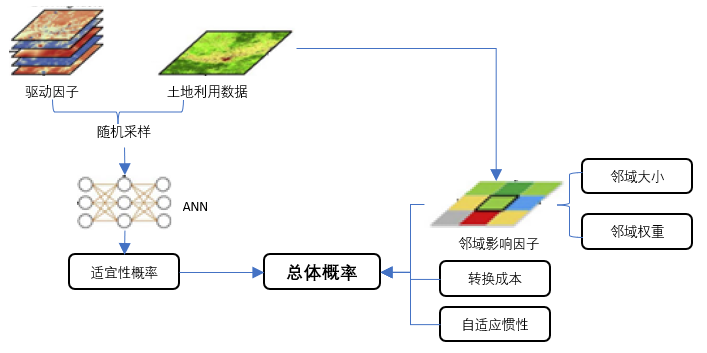
图 总体概率
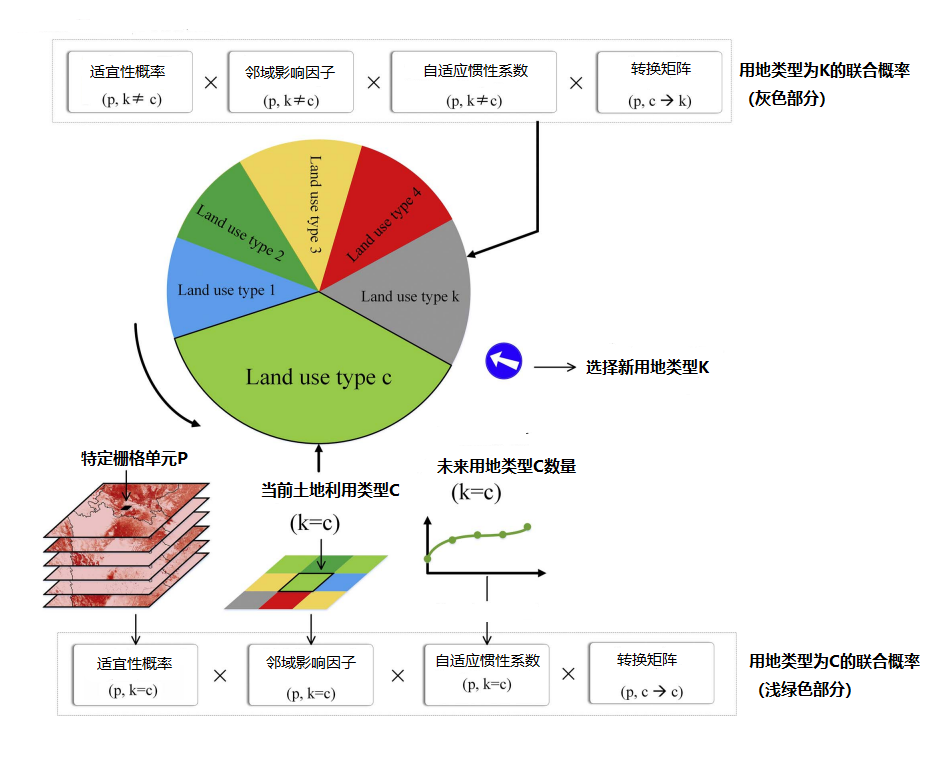
图 轮盘赌原理
结合上面的所有内容,FLUS模型流程大致如下:
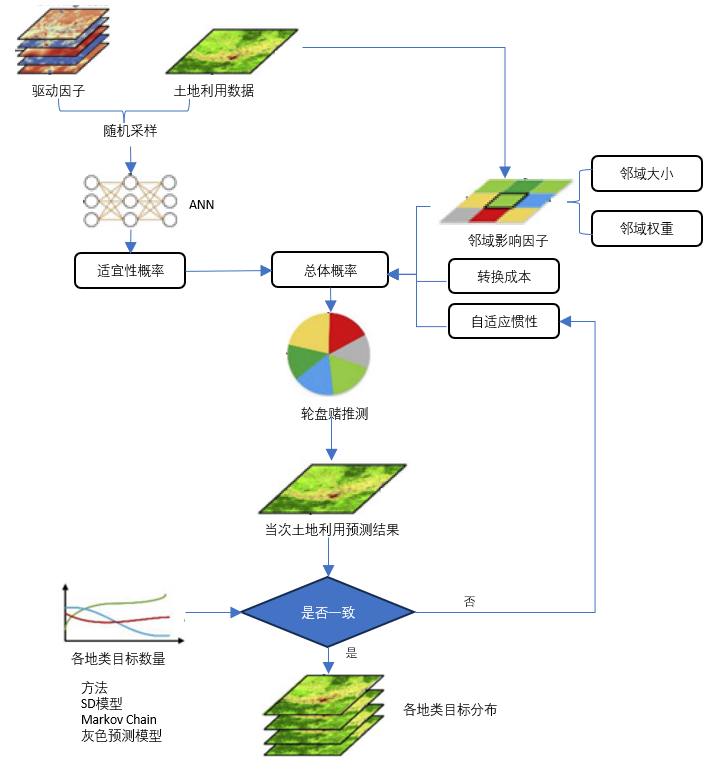
图 flus模型流程
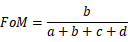

地理时空动态模拟工具介绍(下):
地理时空动态模拟工具的使用方法

整个地理时空动态模拟过程中涉及到的输入数据可以大致分类以下几类。
|
类型
|
文件名
|
数据说明
|
用途
|
|
土地利用数据
|
LUCC2010.tif
|
2010 年土地利用分类数据
|
初始年份土地利用数据,模型输入
|
|
LUCC2020.tif
|
2020 年土地利用分类数据
|
用于验证 FLUS 模型的模拟精度,验证数据
|
|
|
土地利用变化驱动因子
|
dem.tif
|
高程
|
用于计算适宜性概率,代表自然地形影响
|
|
slop.tif
|
坡度
|
||
|
Aspect.tif
|
坡向
|
||
|
Pre2010.tif
|
2010年平均降水
|
用于计算适宜性概率,代表自然环境影响
|
|
|
Pre2020.tif
|
2020年平均降水
|
||
|
tmp2010.tif
|
2010年平均气温
|
||
|
tmp2020.tif
|
2020年平均气温
|
||
|
Road.tif
|
距公路距离
|
用于计算适宜性概率,代表交通区位影响
|
|
|
Railway.tif
|
距铁路距离
|
||
|
River.tif
|
距河流距离
|
||
|
GDP2010.tif
|
2010年国内生产总值
|
用于计算适宜性概率,代表人类活动影响
|
|
|
GDP2020.tif
|
2020年国内生产总值
|
||
|
pop2010.tif
|
2010年人口分布
|
||
|
pop2020.tif
|
2020年人口分布
|
||
|
转换成本
|
转移矩阵.xls
|
Excel文件
|
m*m的矩阵,m表示土地利用类型的个数。取值0或1
|
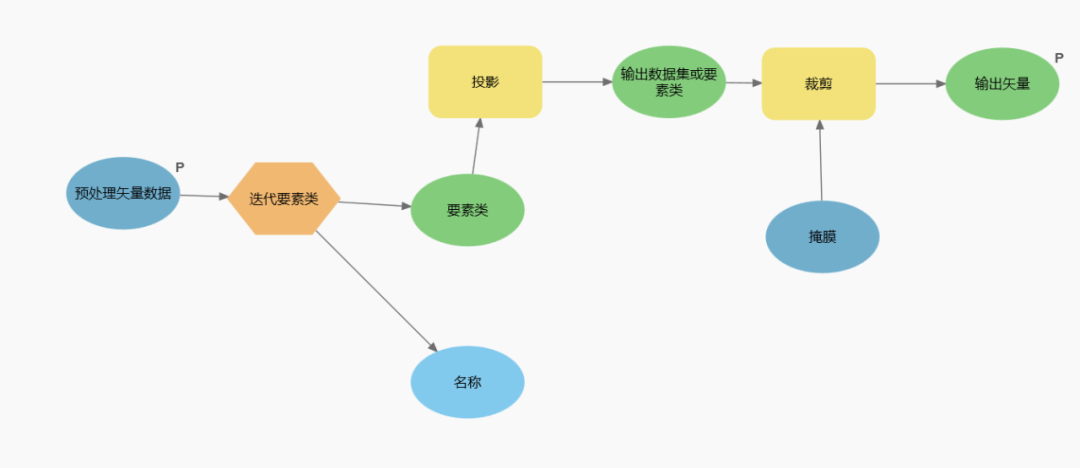
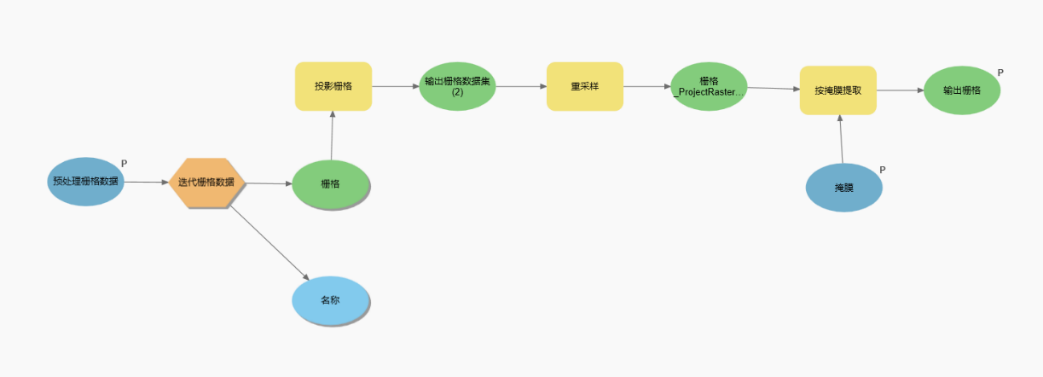
图 矢量栅格数据预处理示意图
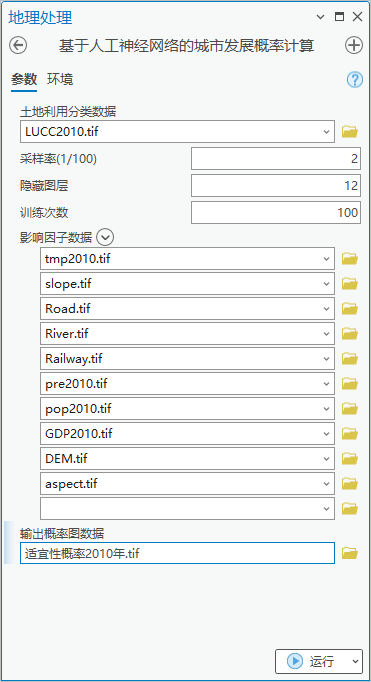
图 基于人工神经网络的城市发展概率计算
ANN输出的结果是一个n波段的概率栅格数据,n为输入数据的类别,本例共有六种地类,因此为6波段,每个波段代表每种土地利用类型的发生概率。
在地理处理工具箱中,找到地理时空动态模拟工具箱,双击【元胞自动机城市发展模拟】工具。工具中的参数数量较多,为便于理解,我们将工具参数顺序进行调整,依次介绍。
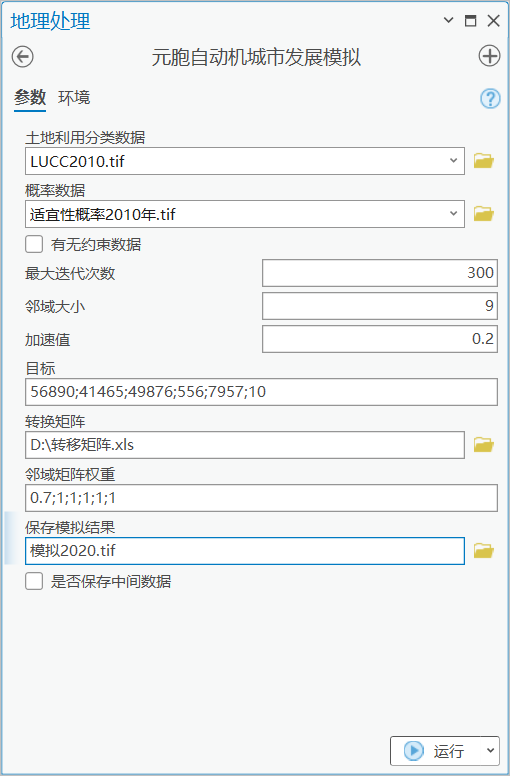
图 元胞自动机城市发展模拟
【土地利用分类数据】参数与ANN工具中的数据一致。
【目标】表示目标像元数,即未来各类土地利用类型的面积。目标值的输入以分号分开,分号隔开的个数和土地利用数据类别相等。当计算结果达到目标时,程序计算完毕。通常根据需要研究区域的实际地区的实际发展情况,采用专家经验或土地利用数量预测模型预测出未来各类土地的需求。即上篇提到的FLUS模型中的目标数量。(这里我们使用2020 年土地利用分类数据中的统计结果)
【概率数据】表示各类用地的分布概率,即ANN工具计算的结果。
【邻域大小】窗口大小,表示以当前像素为中心所影响的范围。比如邻域大小为9,表示窗口的大小为9*9。
【邻域矩阵权重】参数表示各地类的扩张强度,范围为 0~1,越接近 1代表该土地利用类型受邻域的影响更大。以逗号隔开,如0.9;1;0.3;1;1。邻域权重用分号隔开的个数和土地利用数据类别相等,即和目标对应。
PS:【邻域大小】和【邻域矩阵权重】组成邻域影响因子,表示在邻域范围内,当前像元受其他用地单元的影响。
【转换矩阵】用于表示不同土地利用类型之间相互转换的难易程度。以excel文件的形式提供,转移矩阵是一个m*m的矩阵,m表示土地利用类型的个数。类别编码的值必须从1开始,依次类推,直到m。当一种土地类型允许向另一种类型转化时,对应的转换成本值设置为1;如果不允许转化,则参数设置为0。
格式如下:
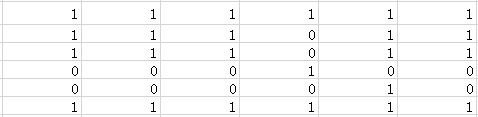
图 转换矩阵
结合上文提到的用地类型,上图表示水域和城市用地无法转换成其他用地类型,林地和草地无法转换成水域。
适宜性概率、邻域影响因子、转换成本以及自适应惯性系数(无需输入),即可得到总体转换概率。
【最大迭代次数 】当程序运行的结果达到目标期望时,程序停止继续迭代,也就是说程序运行的次数可能会小于该值。
【加速值 】当模拟的图像范围比较大时,模型运行较慢。可以将因子设为一个较大的值(0 到 1 之间)以加快土地利用变化的转化速率。
【有无约束数据】是可选参数,如果选择了约束数据,表示禁止限制区域内的土地类型相互转化,例如保护区、宽阔水面等限制不可变化的区域。
使用《分类模型评估神器-混淆矩阵》文章中提到的混淆矩阵工具,对预测的数据进行评估。
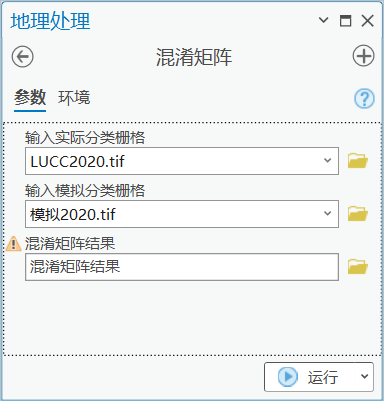
图 混淆矩阵
其结果如下:
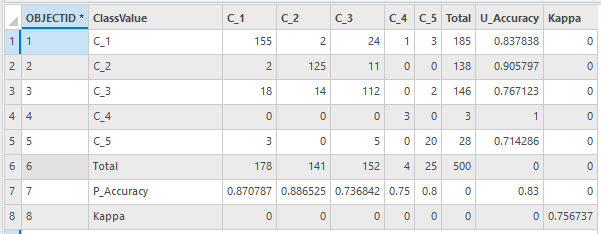
图 混淆矩阵属性表
Kappa系数为0.757,总体精度为0.83。
GeoScene Pro中没有直接提供Fom指数计算的工具(后续版本中将会增加),可以根据Fom指数的计算公式实现,其公式如下
式中:a是实际为变化而预测为不变的误差区域;b是实际与预测均为变化的正确区域;c是实际变化与预测变化不一致的误差区域;d是实际为不变而预测为变化的误差区域。
这里提供一个简单的小工具(识别如下二维码进行下载)。

下载工具 fom指数.tbx
链接: https://pan.baidu.com/s/1m3bAB6DVw0mIfURtWmdnDw?pwd=u2an
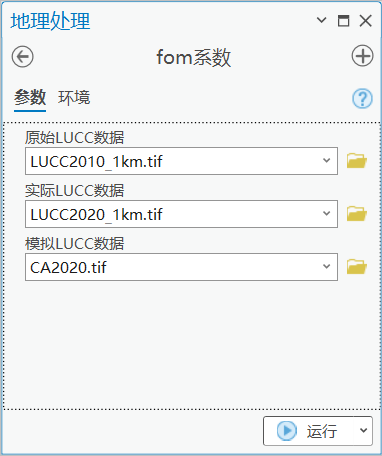
图 fom系数
运行结束得到fom指数。
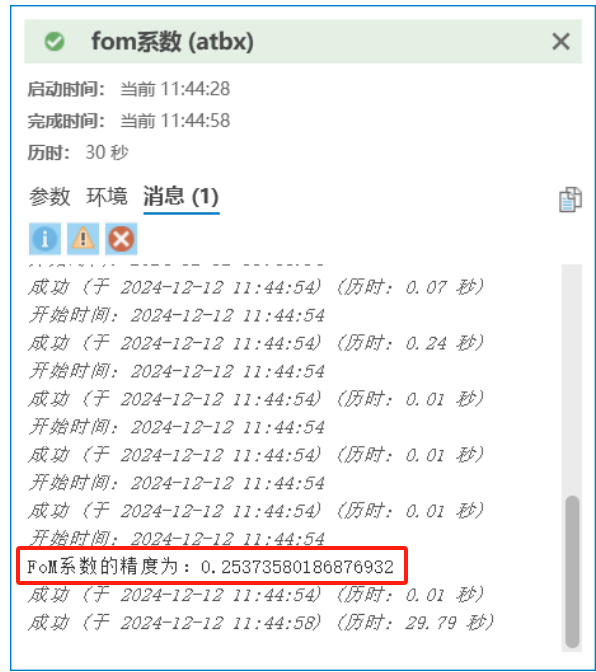
图 fom系数结果
该工具后续会集成到GeoScene 软件中。
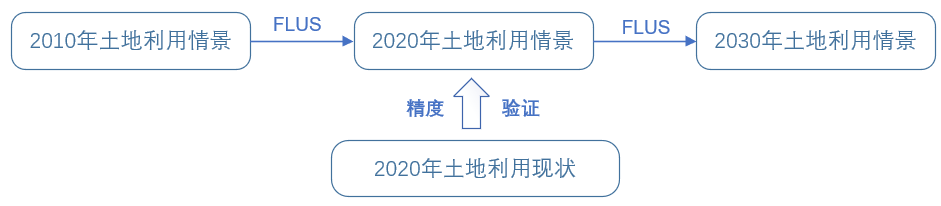
根据上两步可以得出Kappa系数大于0.75,总体精度在83%,fom指数为0.254,FLUS 模型的模拟精度较高,即能够较好地呈现真实的土地利用发展形态,因而将其应用于预测未来用地发展的可靠性也较高。
判断模型可靠性后,就可以继续使用ANN和CA工具预测2030年的土地利用发展情况了。这里记得对于人口、GDP、道路数据等影响因子及时更新,并使用专家评估或者马尔科夫链等方法预测目标数量。
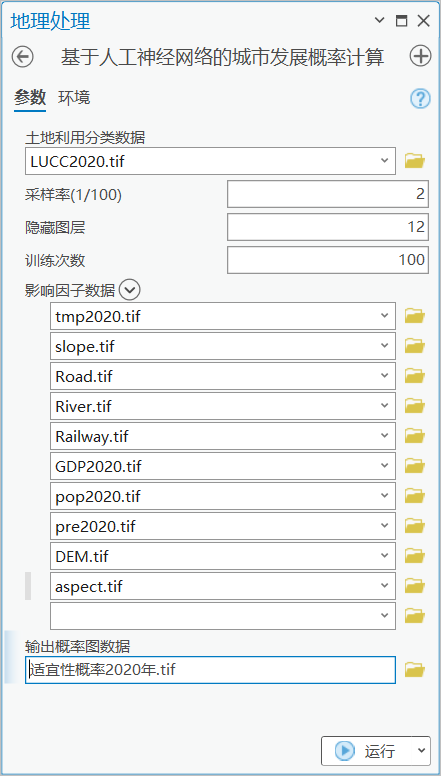
图 ANN计算2020年概率
常见问题
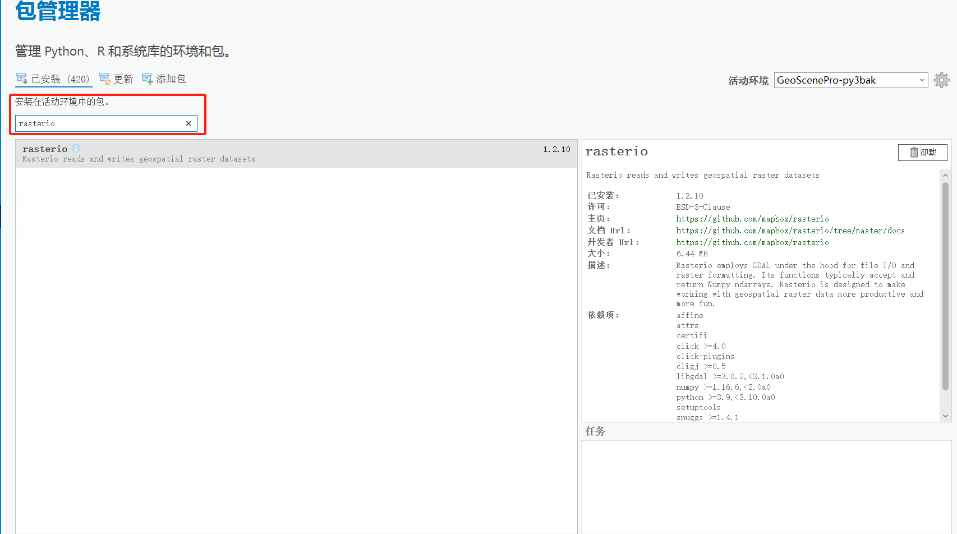
1. 运行ANN工具时,报No module named ‘rasterio’错误。

问题原因:缺少对应的依赖包。
解决方法:在菜单栏【工程】|【包管理器】,对python环境进行克隆。手动克隆方法可以参考https://zhihu.geoscene.cn/article/4009。
并设置克隆后的环境为活动环境。在列表中搜索rasterio,进行安装。
2. ANN工具运行,出现WARNING:TensorFlow 警告,工具执行失败。

问题原因:TensorFlow版本问题,GeoScene 4.1之后不再报错。
解决方法:直接忽略,工具实际是执行成功的。
3.ANN工具,报工具无法打开的错误。
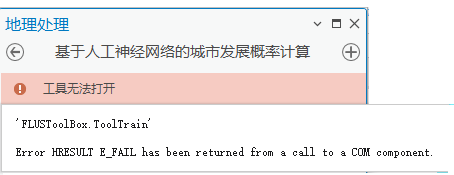
解决方法:重启Pro软件或重启机器。
4.CA工具运行报ValueError: invalid literal for int() with base 10: ” 错误。

问题原因:输入的目标或邻域权重矩阵中“;”号不是半角,或者输入数据有空格。
5.CA工具报目标和邻域权重数据个数不匹配错误。

问题原因:土地利用分类数据的类型与邻域矩阵权重数量不一致,或土地利用分类数据的NoData值异常。
排查以下情况
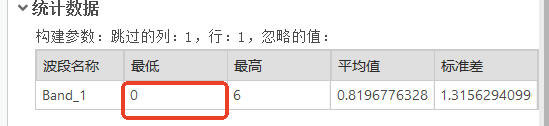
-
土地利用分类数据在统计数据中是否最低值为1。
2. 栅格信息中NoData值是否为空。
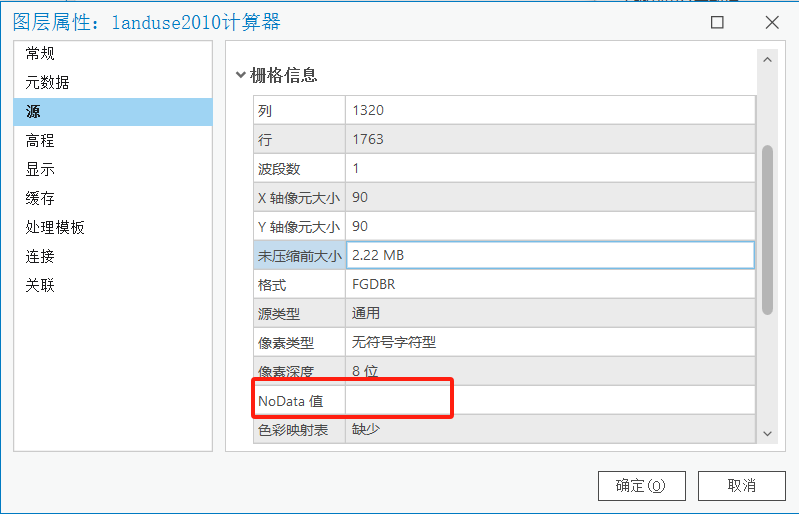
3. 概率数据的波段信息是否与土地利用分类数据类型数量一致。
4. 目标数量是否与土地利用分类数据类型数量一致。
5. 转换矩阵M*M结构,M是否与土地利用分类数据类型数量一致。
6. 邻域矩阵权重数量是否与土地利用分类数据类型数量一致。
解决方法
-
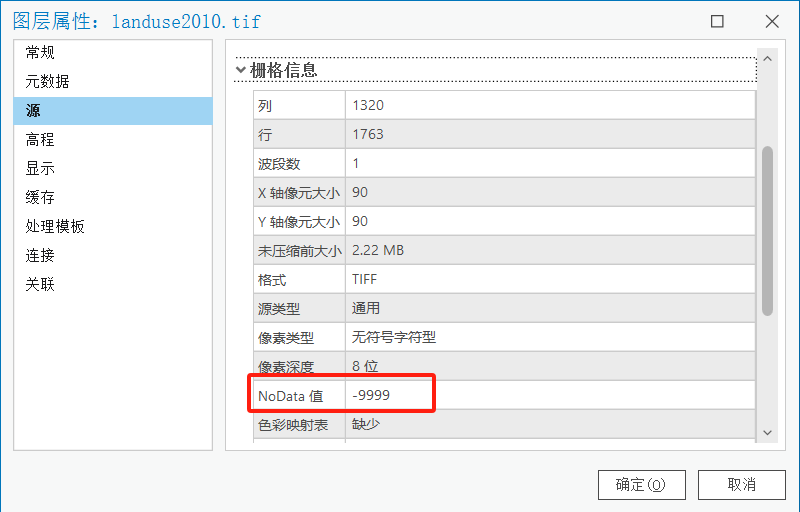
首先使用识别工具,确定0值实际代表的是NoData。且在栅格信息NoData值为空或者其他数值。确定符合上述条件,再使用下方工具。
或
方法1:使用栅格计算器
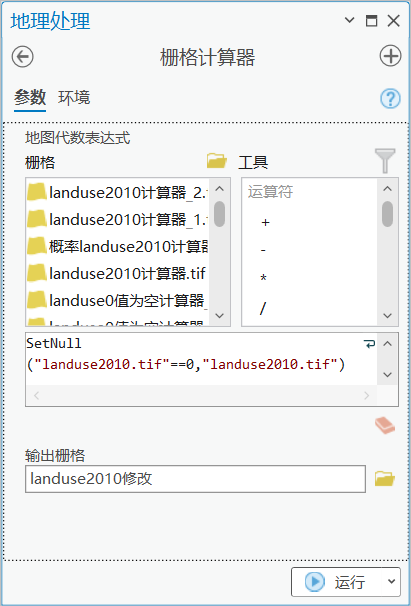
构建新的栅格,将0值设置为NoData。
在内容列表中找到该栅格,右键导出栅格,NoData值设置为0.
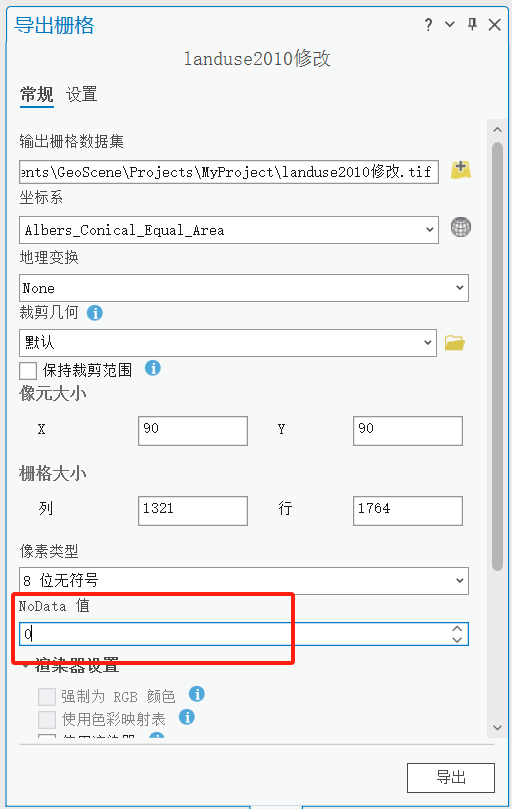
方法2:
在python环境中输入如下代码
ras=arcpy.Raster("landuse2010.tif")ras.noDataValue=0ras.save("D:\nodata2010.tif")
2. 在内容列表中找到该栅格,右键导出栅格,NoData值设置为0.
3. 重新计算概率数据。
4. 修改目标个数,并确保用分号分隔。
5. 确保修改转换矩阵确保M数量与分类数量一致,且没有表头等信息。
原文始发于微信公众号(城市数据派):https://mp.weixin.qq.com/s/zjETmzByumWpzPfLDPrCqQ




