 规划问道
规划问道写 在 前 面
大语言模型凭借其强大的语义理解和生成能力成为街头巷尾热议的话题。虽然大语言模型在处理通识性问答方面表现出色,但是在涉及复杂决策的行业领域仍普遍存在“幻觉”现象,且在可解释性、可信性等方面问题突出。在梳理国内外研究现状的基础上,从知识图谱与大语言模型融合的思路出发,提出了城市交通知识增强大语言模型系统架构,探索了提示词工程、检索增强生成、模型融合及智能体构建技术,研发了城市交通知识增强大语言模型(TransKG-LLM),并从数据增强、知识增强、模型增强及任务增强等4个维度进行了实践探索。研究结果表明,所提出的模型可以缓解通用大模型的“幻觉”现象,有助于提升城市交通治理能力的科学化、精细化和智能化水平。

李健
同济大学道路与交通工程教育部重点实验室,同济大学城市交通研究院 副教授 博士生导师
引言
城市交通是新技术、新产业的重要栖息地,是典型的知识、技术密集型行业,涵盖了交通运输、城乡规划、社会学、经济学、管理学等多个学科门类[1],应用场景多样且差异性较大。因此,从业人员对复杂问题的认知水平和新技术的掌握能力是培育新质生产力的关键。现阶段,中国城市交通面临着复杂性提升、决策响应快、科学决策需求高等挑战[2],这些挑战对从业人员的综合素养提出了更高要求,迫切需要提出创新理论方法体系,以提升行业新质生产力水平。
大语言模型(Large Language Models, LLMs,以下简称“大模型”)是生成式人工智能(Generative Artificial Intelligence, GAI)领域的重要分支,是新质生产力的关键技术。自2022年底OpenAI的ChatGPT推出以来,大模型便在全球学术界与产业界引发广泛关注[3],国内外众多机构陆续推出了各自的大模型[4],如Google的Gemini[5]、Facebook的LLaMA[6]、Mistral AI的Mistral-7B[7]、OpenAI的文生视频模型Sora[8],以及近期推出的具备复杂任务推理能力的OpenAI O1[9]等。而在中国,百度的文心一言、阿里巴巴的通义千问、智谱AI的ChatGLM等也在持续跟进,特别是2025年初深度求索公司推出的DeepSeek-R1受到广泛关注。
尽管大模型在处理通识性问答方面表现出色,但在涉及复杂决策的行业领域,仍普遍存在幻觉现象,以及可信性、可解释性差等突出问题。大模型的幻觉现象是指大模型生成内容时由于领域知识覆盖不全导致的训练数据偏差、缺乏事实验证机制,或推理过程中的错误匹配,致使生成不准确或虚假的信息。此外,由于大模型的参数规模庞大且缺乏明确的决策路径,使得其可解释性和可控性较差,难以追溯其生成内容的推理逻辑,在重视因果联系的应用领域难以获得用户信任。近年来从知识工程(Knowledge Engineering, KE)入手,将大模型和领域知识图谱有效融合,可以有效缓解大模型的幻觉现象,增强其在行业领域的适应性,是推进大模型落地应用的重要技术路径。大模型和知识图谱的深度融合是一个新兴研究领域,医疗、金融等行业已经展开了积极探索,并构建了医疗[10]、金融[11]等领域大模型,然而在城市交通行业仍处于早期探索阶段。
本文在梳理国内外研究现状的基础上,从知识图谱与大模型融合的思路出发,提出了城市交通知识增强大语言模型系统架构,探索了提示词工程、检索增强生成、模型融合及智能体构建技术,研发了城市交通知识增强大语言模型(TransKG-LLM),并从数据增强、知识增强、模型增强及任务增强等4个维度进行了实践探索。
大模型研究现状及发展态势
大模型可以分为通用大模型和领域大模型(又称为垂类大模型)。通用大模型是指在大规模数据集上进行训练,具备泛用性的模型。领域大模型通常基于通用大模型进行微调或在特定领域数据上训练,以更好地解决专业领域问题。本节首先介绍通用大模型和领域大模型的发展历程和技术路线,并重点介绍医疗、金融和交通领域大模型发展现状,最后对研究现状进行述评。
1
通用大模型
从发展历程看,语言模型分为统计语言模型、神经网络语言模型、预训练语言模型和大模型4个阶段[4](见图1)。早期的统计语言模型多采用统计方法来预测单词序列概率,如N-gram模型[12]。神经网络语言模型则通过构建神经网络,将单词转换为词向量来进行预测,如Word2vec模型[13]。2017年,A. Vaswani等[14]提出的Transformer模型是语言模型发展的重要里程碑,通过自注意力机制和并行计算的优势,能够更好地处理长距离依赖关系,提高了模型的训练和推理效率。2020年,OpenAI推出的GPT-3模型的参数规模达到1 750亿个,其强大的“涌现”能力标志着进入了大模型阶段。
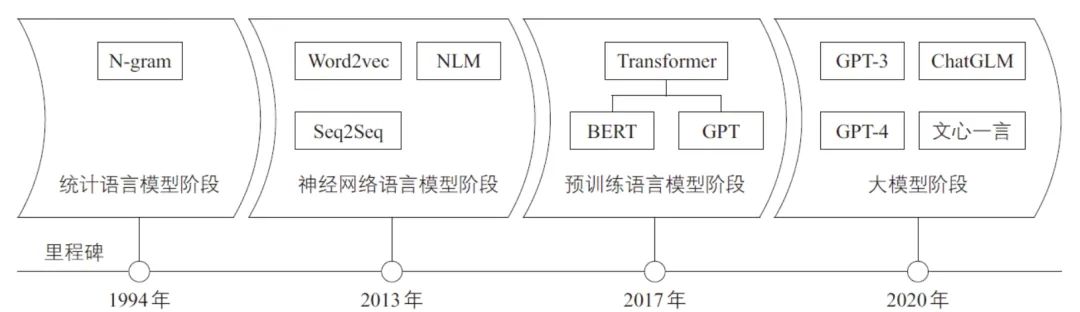
图1 语言模型发展历程
2022年末ChatGPT[15]发布,大模型进入公众视野。近年来大模型正逐步从文本向图片、视频等多模态融合方向发展(见图2),即多模态大模型(Multimodal Large Language Model),显著增强了大模型对现实世界的理解与创造能力,例如LLaVA模型[16]、GPT-4多模态大模型[17]、Sora文生视频大模型等。因训练文本知识结构、知识更新速度、训练成本等原因,大模型在医疗、金融、交通等垂直领域的表现仍然受限,幻觉现象较为明显。
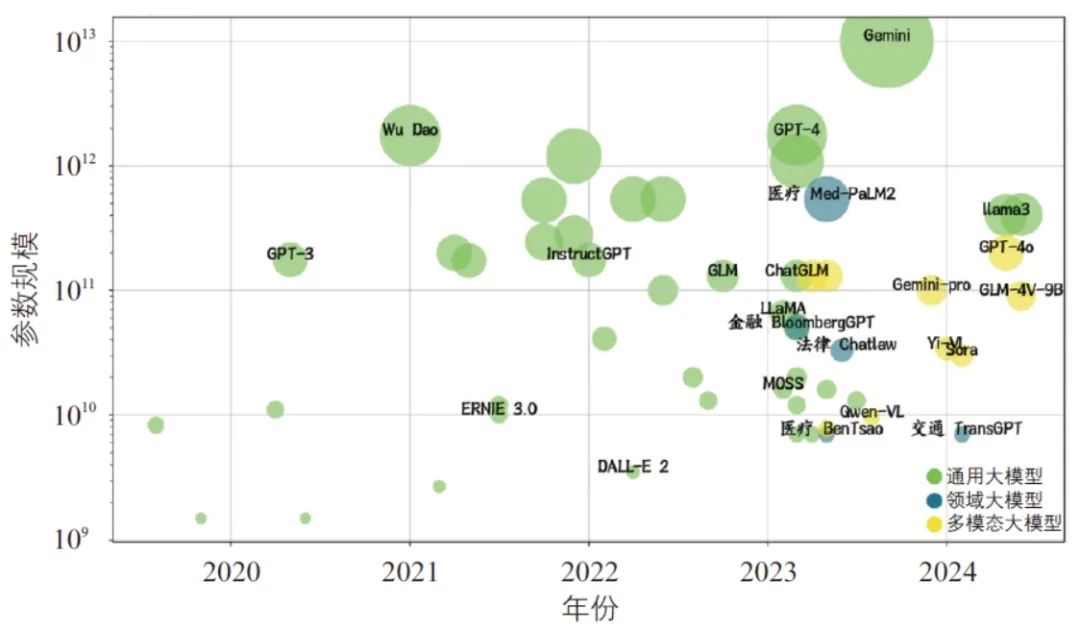
图2 大模型演化历程
2
领域大模型
领域大模型一般基于通用大模型进行训练优化,可以分为内部优化和外部优化两个技术路线。
1)内部优化:通过改变大模型参数(如权重)来增强其在特定领域任务上的表现,主要包括预训练及微调两种方式。预训练是指从大规模无监督数据中学习领域知识,形成参数模型以理解与执行人类世界真实的任务[14];微调是指高效参数微调,通常利用领域标注数据进行有限增量训练,以优化其在特定领域任务上的表现[18]。
2)外部优化:不直接更新大模型参数,通过引入外部知识库或工具来优化大模型在垂直领域的性能,主要包括提示词工程、检索增强生成(Retrieval Augmented Generation, RAG)、模型融合、智能体(Agents)等。提示词工程是指通过提示词来引导大模型产生更准确的输出[19];RAG则预先在外部知识库中存储信息,并在检索过程中采取重排序策略,以辅助大模型生成相关性高的内容[20];模型融合主要采取大小模型优势互补策略,融合大模型泛化能力和行业小模型专业任务理解与处理能力;智能体主要指基于大模型所构建的智能体,通常包括规划、记忆、反馈、执行等模块,用于执行更复杂的任务[21-22]。
综上所述,内部优化可以提升通用大模型在垂直领域的性能,但也存在训练数据量大、成本较高及知识更新慢等问题。而外部优化具有知识更新快、可解释性强、成本低等特点,更易发挥领域知识的积累作用,近年来在领域大模型研发方面得到广泛关注。领域大模型内外部优化方法在领域数据、建设成本、数据安全和输出可控方面的性能对比如图3所示。
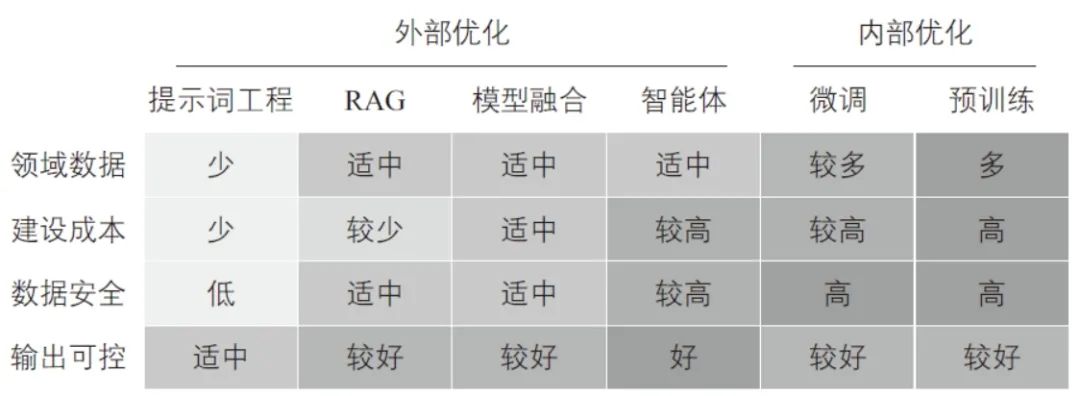
图3 领域大模型内外部优化方法对比
医疗领域大模型
2.1
医疗领域拥有较好的数据和知识图谱基础,较早地在领域大模型方面开展了应用探索。内部优化方面,谷歌的Med-PaLM2[23]通过微调医学领域数据集和提示词优化相结合,显著提升了智能问答系统在医学领域的效果。而PMC-LLaMA[24],则以LLaMA为基础,基于医学领域的学术论文和经典教材,引入知识图谱对大模型进行微调,在多个医学问答基准测试中表现良好。ChatDoctor[25]同样以LLaMA为基础,基于医生与患者对话数据集,并引入外部知识库对大模型进行微调,构建了更加贴近实际医疗场景的问答系统。外部优化方面,MedDoc-Bot[26]在多个大模型的基础上构建了基于医学文档的对话系统。微软通过提示词优化,在无需额外微调的情况下,将ChatGPT的问答能力达到专家水平[27]。医疗领域大模型在应用过程中面临知识训练不充足、长上下文推理技术不成熟等问题[28],仍需进一步的深入研究与探索。
金融领域大模型
2.2
金融领域数据计算量大,且隐私性和安全性要求高,近年来也在尝试将领域专业知识与通用大模型融合,在智能问答、工单助手等场景方面取得了良好成效。内部优化方面,基于领域头部企业的海量数据资源,采用通用大模型与领域知识融合的方式,构建行业领域大模型。基于BLOOM开源多语言大模型,BloombergGPT[29]结合多年金融领域数据进行训练,构建了专注于金融领域的大模型,并在知识问答、推理等任务上表现优异。外部优化方面,主要结合领域知识和内部数据,构建符合领域安全要求的应用,如中国农业银行的ChatABC以问答助手、工单回复助手等形式开展应用;此外,也有结合金融领域专业工具库、模型库来构建大模型驱动的应用,以解决领域的复杂应用问题,如FinGPT[30]是一个专为金融领域设计的开源大模型框架,旨在增强该领域的适应性。鉴于金融领域对隐私与安全的严格约束,行业企业主要将大模型应用于降本增效方面,然而仍面临可解释性及数据隐私保护等挑战。
城市交通领域大模型
2.3
城市交通是一个涉及多学科的复杂领域,更关注系统整体的复杂性、动态性和不确定性[31]。当前,城市交通领域大模型的内部优化主要以开源大模型为基础,如基于ChatGLM进行领域微调的TransGPT[32],其通过微调交通领域的文本和对话数据,训练了面向问答任务的领域大模型,提高了专业知识回答的准确性;TrafficSafetyGPT基于LLaMA对交通安全领域指令集进行训练,弥补了提示词工程能力的限制[33]。而更多研究聚集于大模型外部优化。有研究人员通过提示词来辅助大模型解决复杂的交通问题,例如信号控制[34]、移动行为预测[35]等。也有学者结合提示词优化与多智能体协同来进行监控管理[36]。另外,为增强交通专业模型的迁移性,部分学者将专业模型与大模型融合,共同提升处理复杂任务的能力[37]。此外,也有学者为适配城市交通多模态场景,研究了多模态大模型框架(MT-GPT),采用分层“点线面”结构,为复杂交通系统决策任务提供数据驱动支持[38]。当前,城市交通领域大模型面临领域知识完备性、复杂场景适应性、可解释性等挑战,需加强跨领域知识融合、复杂任务推理能力、模型可解释性等方面的研究。
3
研究述评
领域大模型的研究主要聚焦于两个方向:一是基于内部优化的方式,通过微调增强通用大模型在行业领域的适应性;二是基于外部优化的方式,通过RAG、“大模型+小模型”融合等方法,更好地将通用大模型应用于行业领域场景。内部优化的技术路线需要强大的技术实力、丰富的数据及算力资源,可以实现大模型知识产权保护及应用能力深度定制,但成本高且开发难度大;外部优化的技术路线更注重行业领域数据、知识资源的融合,可以结合场景需求实现研发的快速迭代,加速领域大模型的应用落地。
鉴于城市交通领域的复杂性与动态性,以及大模型训练所面临算力资源和技术人员的需求,采用外部优化的方式是更加切实可行的技术路线。该技术路线主要基于开源通用大模型,通过现有的学科知识、科技文献和行业报告等构建语料库和知识图谱,应用提示词工程、RAG、模型融合及智能体等方法构建领域大模型,来提升对城市交通领域的理解能力和复杂问题处理能力,为城市交通治理提供更加科学化和精细化的决策支持。
城市交通知识增强大模型的构建
1
城市交通领域大模型现状问题产生的原因
通用大模型在城市交通领域应用时面临推理能力不足及“幻觉”问题,原因如下:
1)缺少交通领域高质量语料库。与医疗、金融等领域相比,城市交通在文本数据分析领域的前期积累少,特别是缺乏开源的语料库,使得大模型很难深入理解城市交通领域专用名词、标准规范和演变规律。如在制定交通规划时需要遵循最新的城市规划、环境生态保护、公共安全等法规,而大模型因知识不完备往往无法给出准确的内容。
2)缺少与领域知识图谱的融合。城市交通领域存在场景复杂、多维空间语义信息的理解与分析等难题,导致大模型无法理解城市交通领域决策的内在逻辑,不具备业务的推理能力。如对大模型给出“研判大雨时交通拥堵形势并给出治堵策略”的指令时,由于大模型无法理解“下雨—通行能力下降—拥堵”的内在逻辑,致使无法生成逻辑自洽的内容。
3)缺少与交通专业模型的融合。即使大模型具备交通领域问题识别及内在逻辑分析能力,也难以有效开展量化决策工作。如向大模型提出“基于当前道路拥堵与天气状况,预测并优化下一高峰时段的交通量分配”这样的问题时,由于大模型无法实时调用交通流模型、气象预测模型以及信号控制模型等专业工具进行动态模拟和策略评估,因此无法给出具体路段、时段和信号配时的优化方案,从而限制了其应用效能。
4)领域复杂任务的执行能力不足。尽管知识问答类技术已在诸多领域得到了应用,但在规划方案评估、行业报告自动生成等复杂任务上仍处于初步探索阶段。特别是在涉及多主体参与的交通规划方案征求意见过程中,如何模拟并理解不同参与主体的思维与行为模式,以及如何在复杂任务中实施多轮次的迭代评估与反馈,都是亟待解决的关键问题。为此,需设计出一套科学合理的交通规划方案评估指标体系。
2
融入大模型的决策模式及决策支持系统
如何科学认知城市交通、精准谋划解决实际问题的可行决策对行业从业人员至关重要。城市交通是典型的学科交叉领域,内容涉及社会学、经济学、管理学和工程学等多学科,而且决策需要权衡多方面利益诉求,定量的决策分析方法是提升决策科学化、精细化的关键。在城市交通规划或治理的实践中,用于决策支持的定量模型被广泛应用于问题研判、特征分析和方案评价等工作[39]。随着中国城镇化进入生态文明的新阶段,城市交通的内涵和外延均发生显著变化,从支撑城市发展的先行官转变为空间组织的催化剂,面临有效支撑协同发展、精细治理等一系列高质量发展的新挑战。在此背景下,城市交通决策难度增大,如何合理利用数字化、智能化等新技术提升决策的科学性、精细化和智能化水平成为目前行业关注的热点问题。
决策支持系统自20世纪70年代被提出以来[40],在多个行业领域得到广泛应用。按照驱动要素,决策支持系统的发展可以分为经验判断、模型驱动、数据驱动和人工智能驱动4个阶段(见表1)。经验判断阶段主要依赖决策者的经验,并结合相关的案例和规则进行决策分析[41]。模型驱动阶段对决策者的经验依赖减少,重视采用模型和仿真对策略或方案进行定量评估。数据驱动阶段则更强调将数据分析融入决策过程[42],重视基于数据分析的证据生成,并强调循证决策,即基于证据的决策分析。人工智能驱动阶段充分发挥大模型在人机交互、知识推理和模型融合方面的优势,进一步提升了决策支持的效能。
表1 决策支持系统发展阶段

融入大模型的决策支持系统,在决策模式和系统性能方面有较为显著的变化和提升(见图4)。
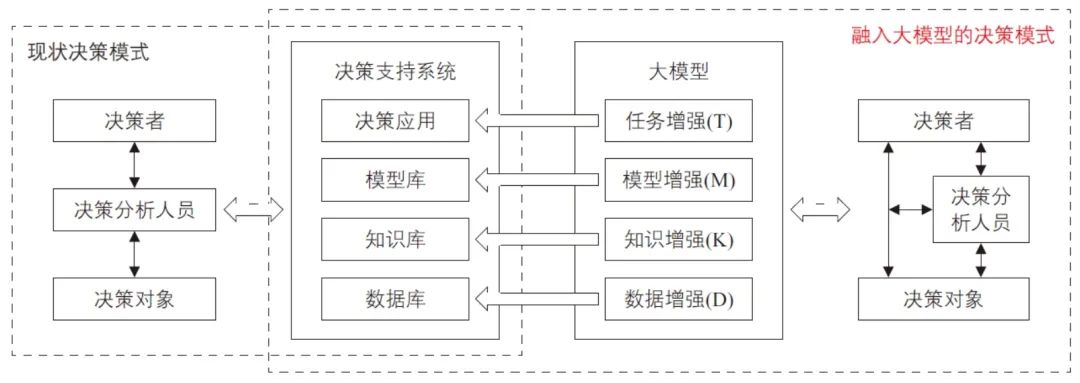
图4 大模型在决策支持系统中的定位和作用
1)在决策模式方面,由于大模型具备复杂情境理解、推理与方案生成能力,可以显著减少决策分析人员的工作。现状的决策模式是“决策者—决策分析人员—决策对象”的三层结构。融入大模型后,针对较为简单且程序化的决策需求,决策者可以直接通过大模型进行交互;针对复杂问题,仍可采取三层结构逻辑,但大模型也可以有效赋能决策分析人员。决策模式由现有的三层结构转变为两层半的结构,而且随着大模型的内外部调优,可以逐渐成为决策信息的辅助制定者、执行者、反馈者与评估者,能够极大地提升决策支持的能力和效率。
2)在决策支持系统架构方面,针对传统的数据库、案例库、模型库和任务库,大模型可以显著增强系统性能。在数据增强方面,引入的大量文本数据有效弥补了传统关系型数据库的不足,通过筛选领域数据集以构建面向城市交通领域的知识资源底座;在知识增强方面,通过构建知识图谱将行业知识体系化,在大模型内外部知识库的支撑下,增强检索覆盖面与生成内容的相关性;在模型增强方面,通过对城市交通专业模型的融合以强化对领域场景的理解、执行与反馈;在任务增强方面,通过构建思维链将复杂任务拆解为若干子问题,引导大模型逐步求解,从而提高决策的准确性与可解释性。此外,大模型多智能体能够模拟真实世界中的多主体决策过程,并借助对话协同机制,在多轮迭代中不断增强决策结果的可解释性与可信度。
3
系统架构
城市交通知识增强大模型(Knowledge-Enhanced LLM for Urban Transportation, TransKG-LLM)的系统架构如图5所示。大模型在城市交通领域落地的关键在于数据利用、信息检索、推理能力提升,同时融合专业模型与实时工具,形成智能体以提升生产力。数据增强主要侧重文本数据处理,并与现有的结构化数据进行融合;知识增强是在前期知识图谱的基础上,结合知识表征、评价等方面的工作,生成可信、可解释的结果;模型增强主要是大模型与现有的行业模型融合;任务增强主要是针对具体场景问题进行智能体设计和协同。
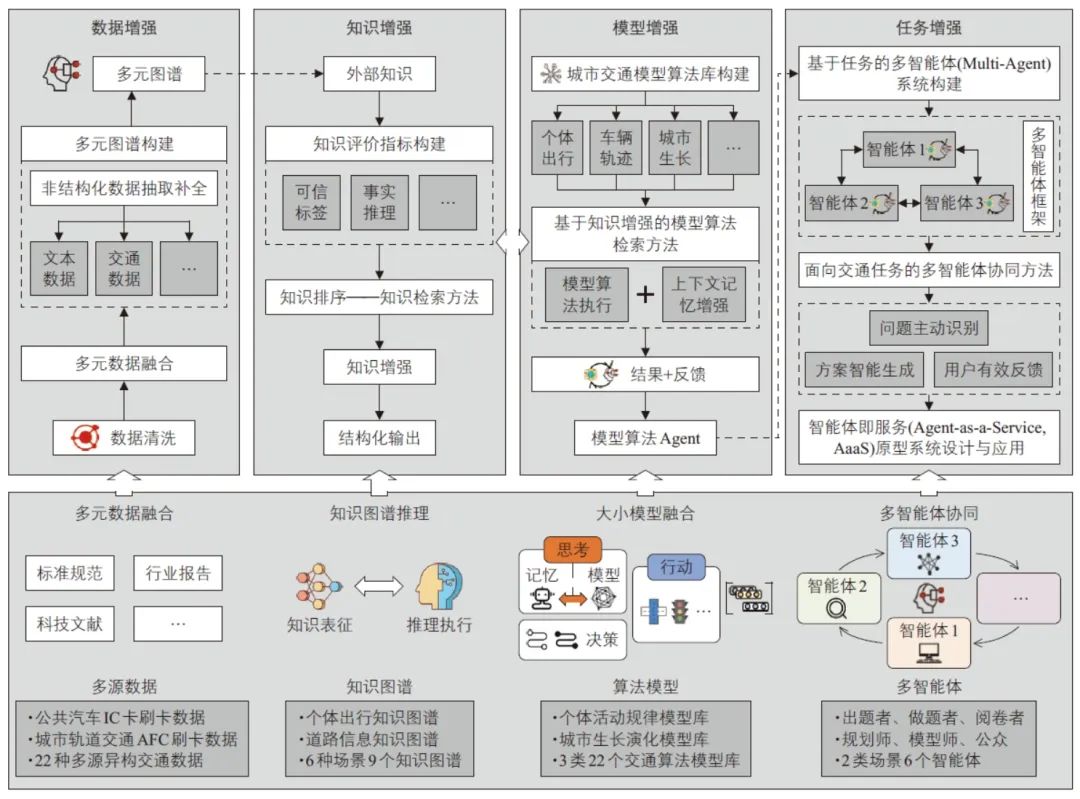
图5 城市交通知识增强大模型系统架构
1)数据增强。
收集和整理本领域的多学科、多场景文本数据。
① 数据收集:收集城市交通领域的标准规范、行业报告、科技文献、调查报告及社交媒体等文本数据。
② 实证分析:面向城市交通主要问题,采用基于实证分析的方法对资料进行筛选和评估,以确保其准确性和可靠性。
③ 构建指令集:采用监督学习的方式,形成带有指令标记的文本对(高质量的问题—符合预期的响应),以增强指令集服务于后续城市交通领域大模型的训练。
2)知识增强。
通过城市交通领域知识图谱系统组织和呈现本领域内的实体及其之间的复杂关系,应用结构化的知识语义网络,使大模型生成过程可控且生成结果可信。
① 离线文本数据加工:首先对海量文本数据进行分段与文本嵌入,随后将分段结果及索引存入向量数据库,使其利用空间相似度检索方法实现高效查询;同时,在完成命名实体识别与关系抽取任务后,对抽取后的三元组进行对齐与补全,实现知识图谱中知识的完备性。
② 在线RAG:接收来自用户输入的查询任务后,先进行知识图谱查询子图的生成和向量数据库的空间相似度检索;然后面向主题对检索结果进行初选与重排序,提升检索命中率和文本生成的相关性;最后通过大模型生成文本并反馈至用户。
3)模型增强。
通过融合领域大模型与交通专业模型,在大模型的泛化能力基础上,增强其在特定领域的专业性。
① 静态交通专业模型管理:明确交通领域专业模型的相关信息,如模型的主要功能、接口参数等,在此基础上进行接口适配以确保互操作性;通过统一的注册平台实现服务信息的管理与查询;根据交通专业模型参数生成提示词,为大模型调用提供指引。
② 动态交通专业模型交互:根据用户需求生成初步响应方案及所需内外部资源,路由至外部交通专业模型,以完成具体场景下的特定任务,然后充分评估模型输出,并利用大模型生成人类可理解的结果。
4)任务增强。
基于大模型的多智能体协同框架,实现多个智能体间的信息交互与任务联动,使其具备实现城市交通领域敏捷治理的能力。
① 明确任务目标:通过分析应用场景和业务需求,定义多智能体框架需要解决的问题和达成的目标,为后续的智能体创建与任务编排提供指导。
② 创建智能体及编排任务:根据场景任务及大模型能力边界设计不同角色的智能体,并为智能体分配任务与资源,确保智能体间高效协同,共同完成复杂任务。
③ 多轮迭代与评估:持续优化任务协同执行水平,每轮迭代后,按照预设的规则进行评估,旨在判断既定条件的完成情况。
应用探索
基于上述技术路线,在前期大规模知识图谱积累的基础上,探索提示词工程、RAG、模型融合及智能体技术,并从数据增强、知识增强、模型增强及任务增强四个维度进行了城市交通知识增强大模型的实践探索。此外,进一步探讨了该模型在应用场景中的研发难度(见图6),旨在为城市交通领域智能化转型提供参考。
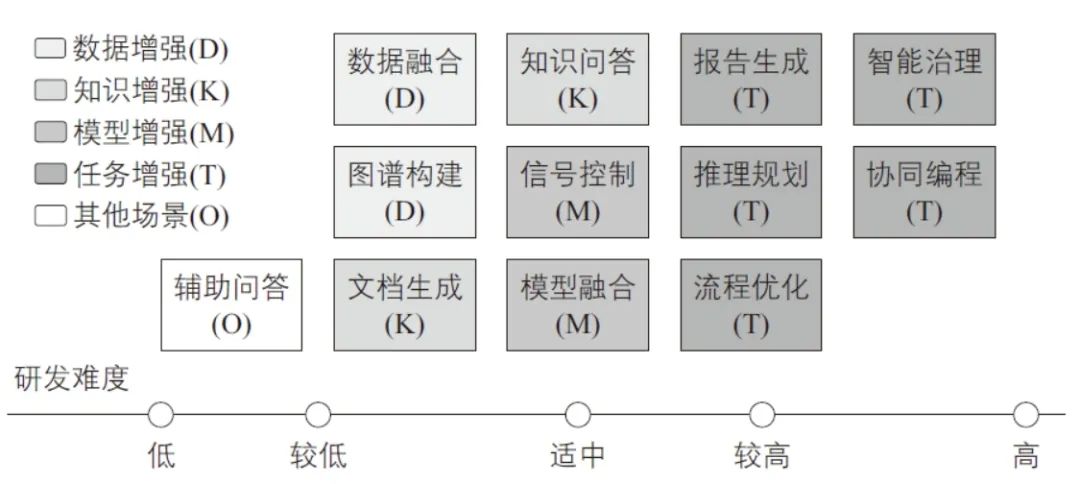
图6 城市交通知识增强大模型应用场景及研发难度对比
1
数据增强:融合多源数据的城市交通领域知识图谱构建
多源数据融合是解决数据孤岛、提升数据价值的关键。知识图谱具备较强的知识组织与表示能力,为城市交通领域数据融合提供了新技术路径。其技术实现主要包括本体设计、知识抽取、知识融合、知识推理等任务(见图7)。
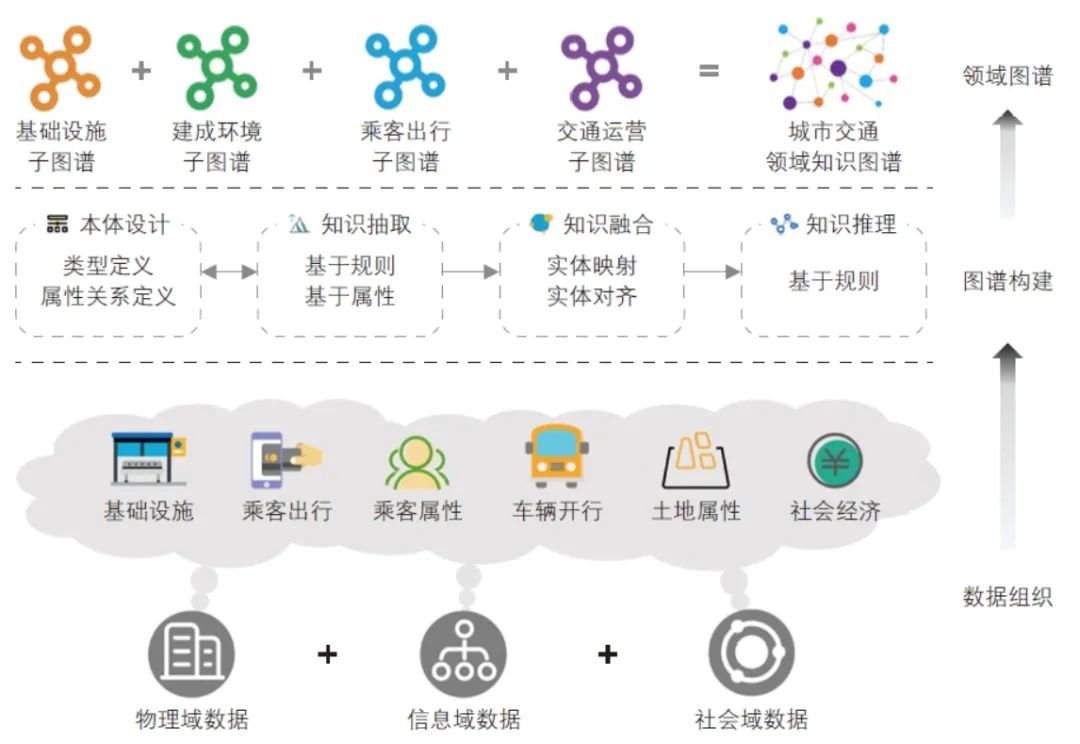
图7 城市交通领域知识图谱构建示意
1)本体设计:作为知识图谱的核心结构,本体定义了领域内的基本概念和实体,通常包括本体分层设计、本体属性设计及本体关系设计。
2)知识抽取:旨在从非结构化或半结构化的文本数据中提取实体、关系及属性等信息,如基础设施、建成环境、乘客出行、交通运营等。
3)知识融合:将不同数据源抽取的知识进行对齐、映射等操作,以形成统一、高质量的知识体系。
4)知识推理:通过具有准确且可解释特性的规则推理支撑多样化的智能决策。
对城市交通领域文本数据进行收集整理,以学科知识为基础串联城市交通场景信息,搜集了包括标准规范、行业报告、科技文献、社交媒体、学科教材、人大代表提案等高质量的文本数据。按照顶层—领域—任务进行城市交通领域知识图谱本体设计,利用大模型和规则学习方法实现文本数据的智能抽取融合,通过知识抽取与知识融合构建了涵盖万级实体的城市交通领域知识图谱。在沉淀城市交通领域核心知识要素的同时,也为领域大模型的研究与实践提供了知识资源底座。
2
知识增强:融合知识图谱与通用大模型的交通行业知识问答
知识增强是通过知识图谱系统组织和呈现本领域实体之间复杂关系的过程,应用结构化的知识语义网络,使领域大模型生成过程可控且生成结果可信。本文针对通用大模型在领域应用中如何消除“幻觉”的挑战,构建了领域知识图谱和通用大模型相融合的知识问答系统,以更有效地服务行业知识问答需求。其技术实现主要包括知识表征、知识检索、知识输出及知识更新四个部分(见图8)。
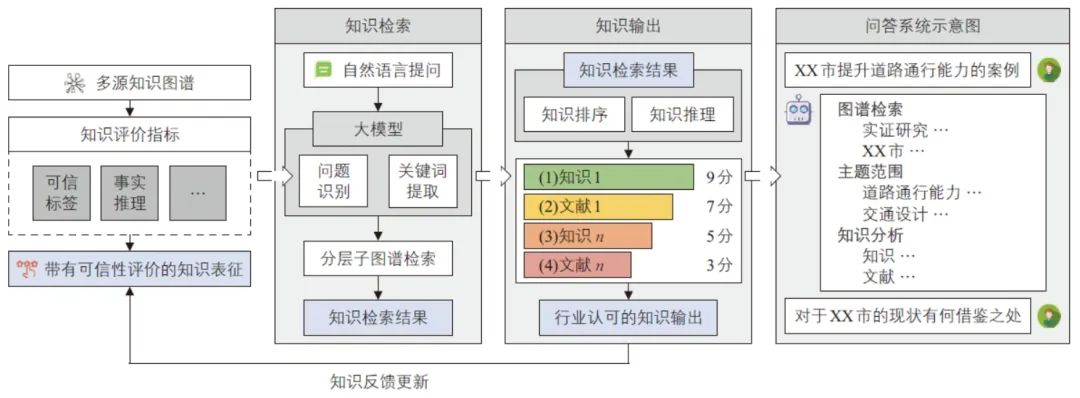
图8 城市交通行业知识问答系统
1)知识表征:通过引入可信标签来确保知识来源的可靠性和权威性。
2)知识检索:通过大模型的自然语言处理能力,识别用户问题及提取关键词,随后在子图中完成检索操作。
3)知识输出:主要包括知识排序与知识推理,前者确保按可信度与相关性进行内容排序,后者在此基础上进行内容生成。
4)知识更新:通过反馈持续更新、修正及补充知识至领域知识图谱中。
面向交通治理的科学决策需求,以低碳出行行为干预为场景,构建了基于科学文献的循证(evidence-based)知识图谱,可以支持领域大模型输出可信科学证据。研究提出了证据分类、分级的方法,并支持对证据进行荟萃分析(meta-analysis)。决策者或决策分析人员可以根据特定情境和目标,结合城市特征,通过查询循证知识图谱获得证据,包括候选证据、证据等级及相关特征(见图9)。在此基础上,借助领域大模型构建的问答系统,决策者或决策分析人员能够根据实验场景和人群进行提问,从而快速和有效获取可信的科学证据。
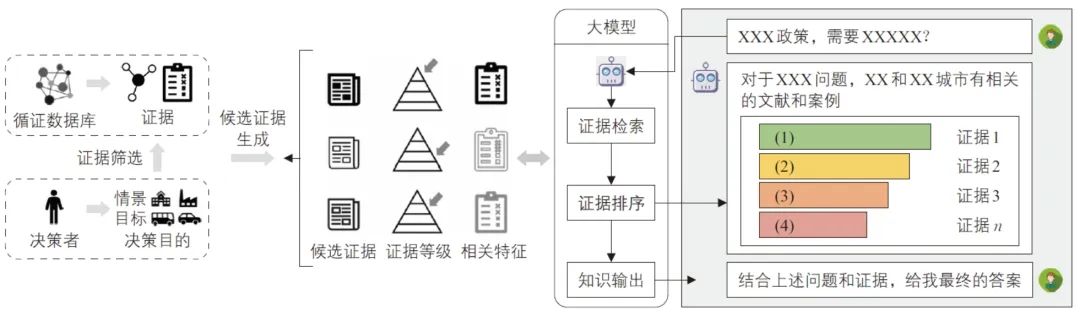
图9 面向低碳出行行为干预循证决策的问答系统
3
模型增强:城市出行规划智能助手
模型增强是基于通用大模型的泛化能力,嵌入专业小模型的行业知识与业务理解能力,实现领域大模型面向具体交通场景的分析与应用。以交通规划中的出行特征分析为例,本文利用大小模型融合的方法,研发了城市出行规划智能助手(见图10),其主要功能包括:
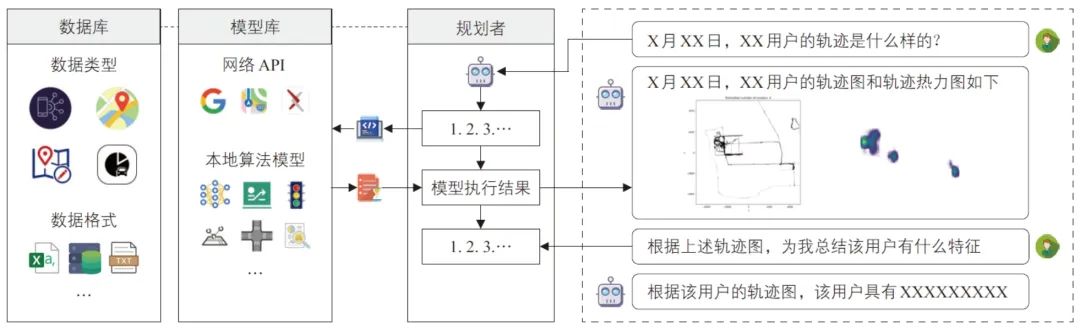
图10 城市出行规划智能助手系统
1)数据库:作为信息存储与处理中心,集成了海量的城市交通数据,包括但不限于道路网结构、用户轨迹及出行需求等信息。
2)模型库:作为智能助手实现自主规划的能力支撑,通过集成在线与本地算法模型库,实现城市出行规划任务的自动执行。
3)规划者:在领域业务理解的基础上将复杂任务分解为可执行子任务,并路由至相应的算法模型服务,在任务执行过程中不断进行评估与效果评价。
基于上述方法,面向出行行为分析的场景,构建了包含数十万条用户轨迹数据的数据库和10余个出行行为分析小模型的模型库,结合模型增强实现了出行行为在大尺度视角下的空间分析、模式识别和小尺度视角下的出行方式预测、轨迹预测。在所构建的模型库的基础上,对主流的开源、闭源模型进行测试。在进行提示的情况下,本文所使用的模型增强方法中小参数模型命中率均超过80%;在不进行提示的情况下,主流的大参数模型命中率也均达到80%以上(见表2)。
表2 模型增强测试结果 (单位:%)

4
任务增强:基于多智能体的教学智能助手
任务增强是以领域任务为导向,通过通用大模型的多智能体协同框架实现多个智能体间的信息交互与任务联动,使其具备解决领域任务的能力。本文以交通工程课程为例,设计了教学、考核等多智能体及其协作机制,研发了课程智能教学助手(见图11)。
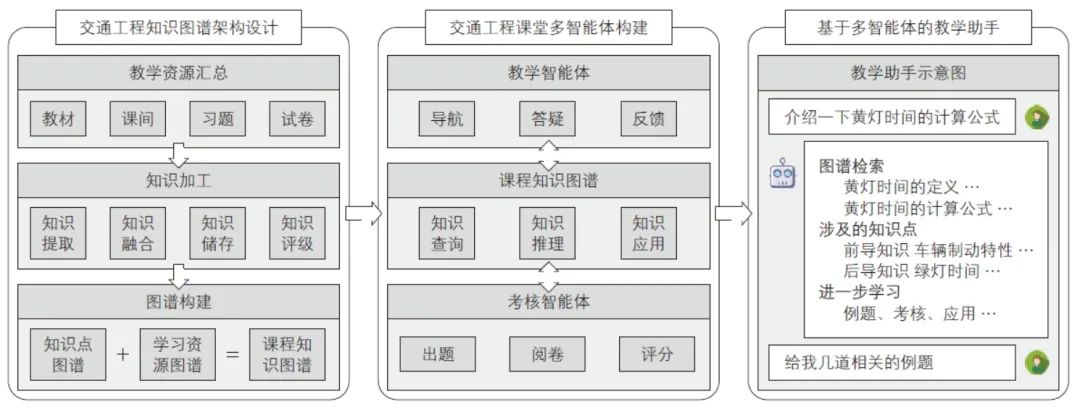
图11 课程智能教学助手示意
1)课程知识图谱构建:对教材、课件、习题和试卷等教学资源进行知识提取、融合、存储与评价。
2)教学智能体:主要包括导航、答疑和反馈三个模块。导航模块依托知识图谱和领域大模型生成可定制化的学习大纲;答疑模块通过自然语言处理技术实时解答学生的问题;反馈模块生成个性化的学习报告以优化学习效果评价。
3)考核智能体:包括出题、阅卷和评分三个模块。出题模块利用知识图谱、题库数据自动生成题目;阅卷模块结合光学字符识别(Optical Character Recognition, OCR)技术和自然语言处理技术实现自动批阅与评估;评分模块基于多维评分体系进行考题完成水平的评价。
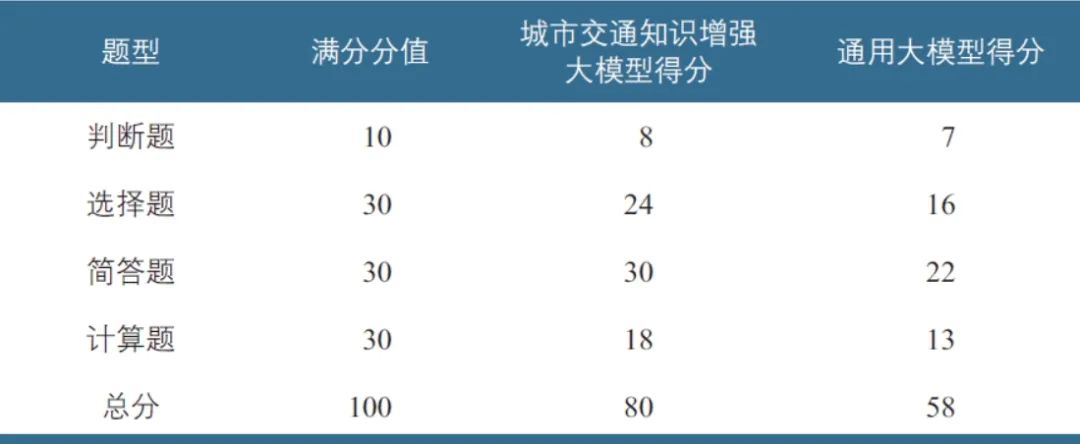
基于上述方法,本文采用某大学交通工程期末考试试卷作为测试对象,以专业知识点的问答作为测试集,对比分析了城市交通知识增强大模型和通用大模型的结果。实验结果表明,知识增强技术能够有效缓解通用大模型的“幻觉”现象,提升通用大模型在交通工程专业知识理解、细节识别和计算准确性上的稳定性和准确性。表3是试卷评估结果,城市交通知识增强大模型在各类题型准确率方面均有显著提升,优于通用大模型。此外,在知识点问答方面,城市交通知识增强大模型也有优异的表现。例如,在通行能力类别及大小关系的问答中,城市交通知识增强大模型能够准确回答理论通行能力、实际通行能力和设计通行能力及其大小关系,而通用大模型的回答则是泛泛而谈;在黄灯时间计算问题中,城市交通知识增强大模型可以给出正确计算,而通用大模型不能给出准确的计算结果。
表3 某大学交通工程期末考试试卷评估结果
结束语
作为人工智能领域的重要分支,大模型在城市交通领域展现出广泛的应用前景,其语义理解、文本生成及逻辑推理等能力为城市交通管理决策提供了有力支撑。从技术路线看,采用外部优化的方式,基于现有的开源通用大模型,通过已有的学科知识、科技文献和行业报告等构建语料库和知识图谱,探索提示词工程、RAG、模型融合及智能体等方法,是推进城市交通领域大模型更加切实可行的方式。然而,城市交通领域尽管积累了大量的结构化数据和定量分析模型,但在行业知识图谱构建、大模型和行业模型融合、智能体设计等方面仍缺少研究积累,这些方面限制了大模型“泛化”与领域“专业”需求的有效衔接。未来需要结合具体场景进一步完善知识图谱和知识增强大模型,并通过产学研协作打造城市交通领域大模型开源生态,提升城市交通治理能力科学化、精细化和智能化水平。
《城市交通》网络首发文章
DOI:10.13813/j.cn11-5141/u.2024.0046
作者:李健,朱国军,王奥,夏强,周胥君,李毅喆

点击“阅读原文”查看
“观点集萃”栏目更多内容

采编平台

微博

官网

视频号
关注解锁更多精彩

2025034期
编辑 | 张斯阳 耿雪 张宇
审校 | 耿雪
排版 | 张斯阳
原文始发于微信公众号(城市交通):李健 | 城市交通知识增强大语言模型构建及应用探索










